Continuing with our initiative to develop optimized and user-friendly keyboard layouts for various Indic languages, we conducted a detailed character frequency analysis for Kannada. Using large-scale monolingual datasets collected from diverse web sources, this study aimed to uncover real-world usage patterns of Kannada characters to inform better design decisions for digital tools. This post lists the outcomes and our findings regarding the detailed character frequency analysis undertaken and how it guided the keyboard layout design for Kannada.
Dataset Overview
To ensure statistical robustness in our analysis, we collected a large Kannada dataset from multiple sources in the web, including from:
- IndicCorp
- Leipzig Kannada Corpus
- Wikipedia articles
- Samanantar v0.3 (En-Indic; Indic-Indic)
- Kannada News Dataset
After data pre-processing and cleaning of the dataset, we arrive at following statistic for this:
- Total tokens: 1.567 billion
- Unique tokens: 14.825 million
This large and diverse dataset provided a solid foundation for analyzing character usage trends across Kannada as being used in modern daya.
Overall Character Frequency Analysis
The core of our analysis is a character frequency heatmap, where vowels are represented in columns and consonants in rows. Each cell in the matrix reflects the frequency of a specific vowel, consonant or consonant-vowel (CV) combination, with color intensity ranging from light yellow (low frequency) to dark purple (high frequency).
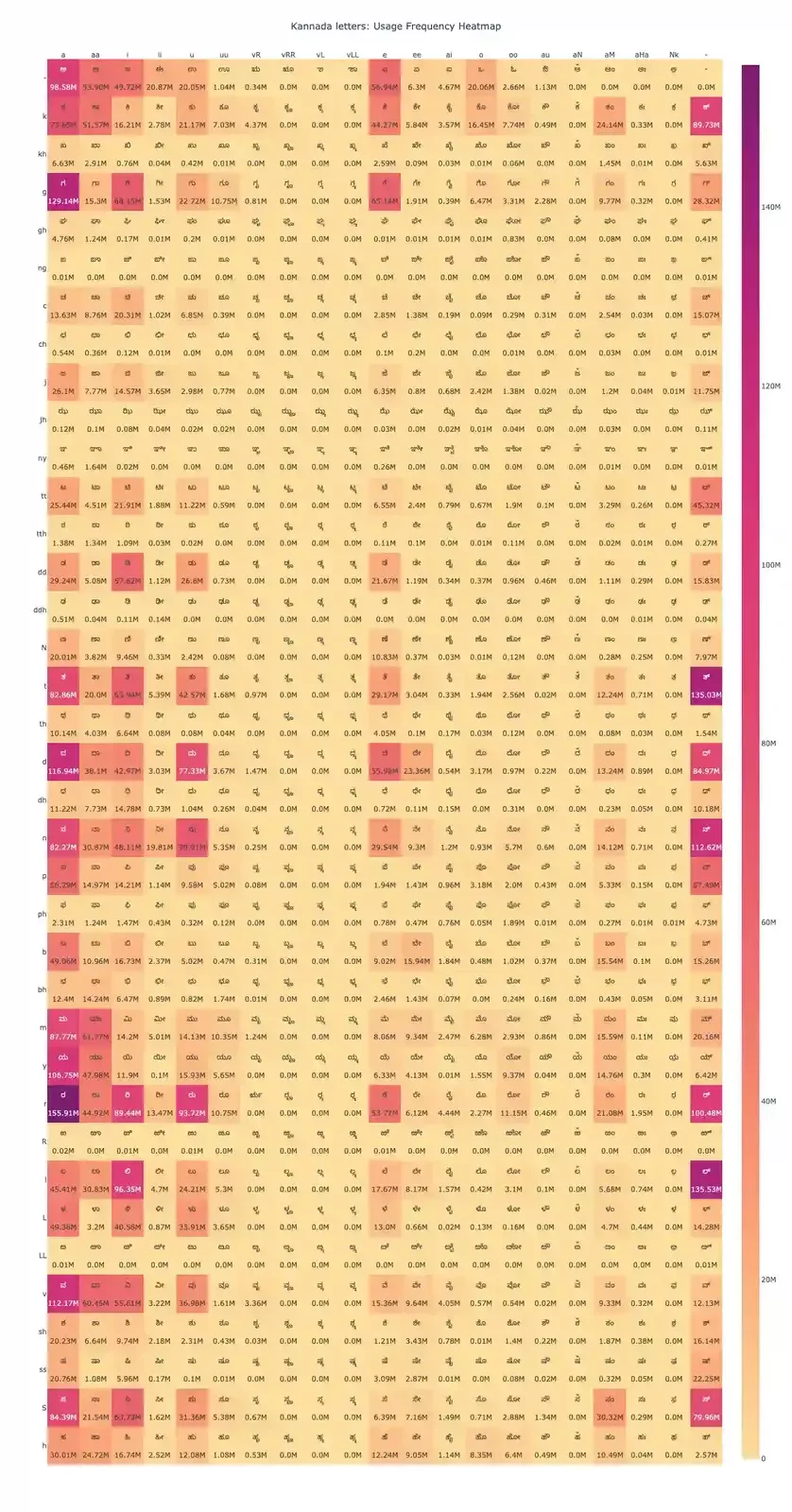
Vowel Frequency Analysis
 As in other Indic languages, the shorter vowels are more frequent than their longer counterparts. The vowels ಅ (a), ಇ (i), and ಆ (aa) are the frequently used either as standalone vowels or as vowel signs in a consonant-vowel (CV). Vowels like ಉ (u) and ಐ (e) also show significant overall usage. The ardhakshara (virama) sign occurs more than in billion instances (last cell in the heatmap) in this dataset, underscoring the frequent use of pure consonants in Kannada. This pattern aligns with other Dravidian languages such as Telugu and Malayalam, where the virama plays a similarly prominent role in forming consonant clusters and suppressing inherent vowels.
As in other Indic languages, the shorter vowels are more frequent than their longer counterparts. The vowels ಅ (a), ಇ (i), and ಆ (aa) are the frequently used either as standalone vowels or as vowel signs in a consonant-vowel (CV). Vowels like ಉ (u) and ಐ (e) also show significant overall usage. The ardhakshara (virama) sign occurs more than in billion instances (last cell in the heatmap) in this dataset, underscoring the frequent use of pure consonants in Kannada. This pattern aligns with other Dravidian languages such as Telugu and Malayalam, where the virama plays a similarly prominent role in forming consonant clusters and suppressing inherent vowels.Consonant Frequency Analysis

Special Characters and Ligatures
Kannada, like many Indic scripts, includes a variety of ligatures and conjunct characters. However, to support commonly used consonant conjuncts in Kannada, we’ve assigned ತ್ರ್ (tr), ಕ್ಷ್ (kss), ಶ್ರ್ (shr), and ಜ್ಞ್ (jny) to the Alt + Shift positions of specific keys on desktop keyboards. On mobile keyboards, where the Alt key is not available, these conjuncts can be accessed by long-pressing the keys Y, U, I, and O, respectively. This design ensures that these frequently used clusters remain easily accessible across both desktop and mobile platforms.
Keyboard Design Implications
Our character frequency analysis for Kannada offers valuable insights for anyone working with the Kannada keyboard layout. From native speakers to developers building Kannada phonetic keyboards, understanding which characters are most frequently used can enhance typing efficiency and user experience. This data-driven look at the Kannada keyboard supports smarter design and localization.
The insights from this frequency analysis plays a key role in designing the Varta Kannada keyboard. Frequently used characters are placed in more accessible positions (home row or index finger positions), while less common ones are assigned to secondary layers (e.g., Shift or long-press positions). This ensures a balance between comprehensive script coverage and ease of use. To improve usability, we opted not to include standalone vowel signs. Instead, vowel signs are generated automatically from consonant-vowel sequences, which simplifies the layout and minimizes input errors.
You can explore our optimized keyboard layout through the Varta Keyboard apps, available on Android and iOS, as well as through browser extensions for Chrome, Edge, and Safari.
Explore Frequency Analyses in Other Languages
We’ve performed similar analysis for other Indian languages as well. Explore them below: