As part of our broader initiative to develop optimized and user-friendly keyboard layouts for various Indic languages, this blog post focusses on our efforts in Hindi. We start with a detailed character frequency analysis for Hindi. Using large-scale monolingual Hindi datasets collected from the web, this study focused on understanding the usage patterns of Hindi characters in real-world text. The insights gained from this analysis played a key role in designing a more intuitive and efficient Hindi keyboard layout, aimed at enhancing typing speed and improving text prediction capabilities on mobile platforms.
Dataset Overview
We collected multiple monolingual Hindi datasets from the web, including the following key corpora.
- IITB Hindi Monolingual corpus
- IndicCorp
- Leipzig Hindi Datasets
- Lindat HindEnCorp 0.5
- IndicNLP News Articles
- Samanantar v0.3 (En-Indic; Indic-Indic)
- Classificataion Datasets (iNLTK, BBC Articles etc.)
After thorough data pre-processing and noise removal, the final dataset comprised approximately 8.92 billion total tokens and around 13.1 million unique tokens. Our character frequency analysis was conducted on this extensive and diverse dataset, providing a robust statistical foundation for our findings.
Detailed Character Frequency Analysis
We began by analyzing the frequency of all the characters in the Hindi alphabet, depicted as a heatmap as a matrix with vowels and consonants shown along the row and column axes respectively. The most frequenct characters are marged in darker colours, while the less frequent ones in progressively lighter shades.
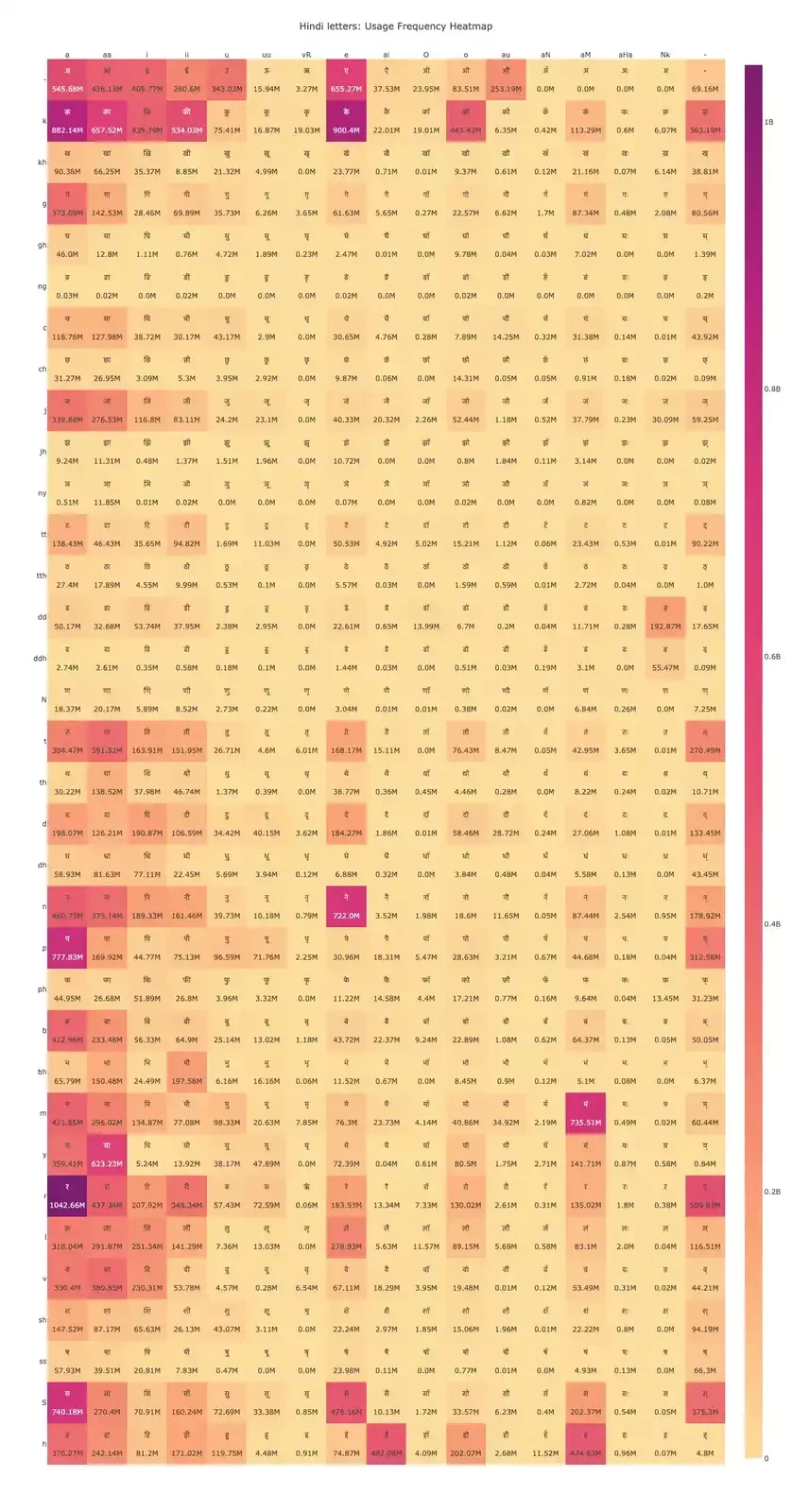
Interestingly, unlike in Dravidian languages or Marathi, Hindi displayed a unique pattern: the vowel ए appeared more frequently than the alphabet-initial vowel अ in its standalone form. However, when it came to consonant-vowel combinations, the अ vowel was more dominant than ए, indicating a distinct usage trend in Hindi text.
Vowel Frequency Analysis
We then analyzed the frequency of Hindi vowels, both in their standalone form (e.g., अ, इ, उ) and when combined with consonants (e.g., का, कि, कु). This was done by summing the columns of our overall character frequency chart. The resulting data highlights which vowel sounds are most commonly used in Hindi text, offering valuable insights for layout prioritization and predictive typing.

The top three most frequently used vowels in consonant-vowel (CV) combinations are अ (a), आ (aa), and ए (e). These vowels form the core of Hindi phonetic structure and are heavily represented across the language. The virama (aka halant) sign (्), used to suppress the inherent vowel and form conjunct consonants, appears 3082.36M times (last cell in the heatmap) —making it the fourth most frequently used glyph in the dataset. This is a notable finding, especially when compared to Dravidian languages, where the virama is often as dominant as the अ CV form. In Hindi, while still highly frequent, it plays a slightly less central role in character composition. Vowels like इ (i), ई (ii), ओ (o), and अं (aṃ) also show significant usage, each contributing meaningfully to the overall character distribution. Characters such as ऋ (vR), औ (au), अः (aḥ), and अँ (aṅ) appear far less frequently, reflecting their more limited use in modern Hindi text.
Based on this analysis and also following our earlier convention for other languages, we laid out the अ, इ, उ, ए, and ओ short vowels in left-hand position of the home row and the long vowels (if applicable) in their corresponding shift key positions. This makes it easier for users to type the most frequent vowels with their dominant fingers.
Consonant Frequency Analysis
Next, we turned our attention to consonants. By summing the rows of the character frequency chart, we identified how frequently each consonant appears across different vowel combinations. This row-wise analysis reveals the most commonly used consonants in Hindi, which is crucial for optimizing key placement and improving typing efficiency.
 The consonants क् (k), र् (r), न् (n), ह् (h), and स् (S) top the frequency chart, with क being the most dominant at 4498.56 million occurrences. These high-frequency consonants are central to Hindi phonology and appear across a wide range of words and contexts. Characters like म् (m), द् (d), य् (y), ल् (l), and प् (p) also show significant usage, each exceeding 1000 million occurrences. These contribute to the core structure of Hindi vocabulary. Aspirated and retroflex consonants such as झ् (jh), ञ् (ny), ङ् (ng), and घ् (gh) appear far less frequently, with ङ् being the least used at just 0.31 million.
The consonants क् (k), र् (r), न् (n), ह् (h), and स् (S) top the frequency chart, with क being the most dominant at 4498.56 million occurrences. These high-frequency consonants are central to Hindi phonology and appear across a wide range of words and contexts. Characters like म् (m), द् (d), य् (y), ल् (l), and प् (p) also show significant usage, each exceeding 1000 million occurrences. These contribute to the core structure of Hindi vocabulary. Aspirated and retroflex consonants such as झ् (jh), ञ् (ny), ङ् (ng), and घ् (gh) appear far less frequently, with ङ् being the least used at just 0.31 million.
Nukta Usage in Hindi Orthography
The Nukta (or nuqta, '़') is a diacritic mark used in Hindi to represent phonemes that are not native to Indic languages but have been borrowed from Arabic, Persian, English, and other foreign sources. In standard Hindi, the use of the Nukta is restricted to a specific set of consonants—seven of which are widely accepted and standardized. Our analysis focuses on the frequency of these seven Nukta-modified characters, as visualized in the accompanying heatmap.
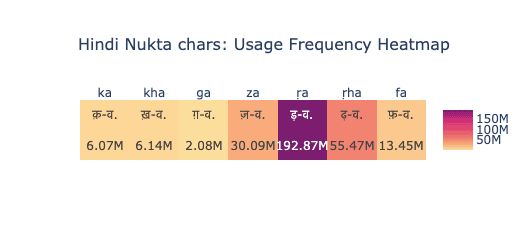
The heatmap reveals significant variation in the usage of these characters. Among them, 'ड़' (ṛa) is the most frequently used, appearing approximately 192.87 million times. This is followed by 'ढ़' (ṛha) with 55.47 million instances, and 'ज़' (za) with 30.09 million. Other characters such as 'फ़' (fa), 'ख़' (kha), 'क़' (qa), and 'ग़' (gha) show moderate to low usage, ranging between 6 and 13 million occurrences.
Importantly, Nukta characters do not combine with the virama and therefore do not form conjuncts. However, they can take vowel signs to form syllabic units, as seen in words like सड़क, पड़ा, खिलाड़ी, and जुड़े. Due to this behavior, unlike regular consonants, Nukta characters are represented in their full CV (consonant-vowel) form—typically the akāra form—in the Varta keyboard layout. To maintain intuitive typing, these characters are mapped to the same key positions as their base consonants, accessible via Alt + Shift on desktop keyboards or through long press options on mobile keyboards.
Special Characters and Ligatures
Hindi, like many Indic scripts, includes a variety of ligatures and conjunct characters. To support commonly used consonant conjuncts in Hindi, we’ve assigned त्र् (tr), क्ष् (kss), श्र् (shr), and ज्ञ् (jny) to the Alt + Shift positions of specific keys on desktop keyboards. On mobile keyboards, where the Alt key is not available, these conjuncts can be accessed by long pressing the keys Y, U, I, and O, respectively. This design ensures that these frequently used clusters remain easily accessible across both desktop and mobile platforms.
Keyboard Design Implications
If you're exploring the Hindi script and its usage patterns, understanding the Hindi keyboard layout is essential. Whether you're using a Hindi phonetic keyboard or a traditional Hindi keyboard, character frequency insights can help optimize typing experiences and input methods. This analysis sheds light on how Hindi characters are used in real-world text, informing better design for digital tools and keyboards.
The insights from this frequency analysis directly inform our strategy for designing Varta Hindi phonetic keyboard. Frequently used characters are placed in more accessible positions (home row or index finger positions), while less common ones are assigned to secondary layers (e.g., Shift or long-press positions). This ensures a balance between comprehensive script coverage and ease of use. To simplify the design and reduce typing errors or invalid glyph combinations, we chose not to include individual vowel signs. Instead, the system automatically generates the correct vowel sign based on the consonant and following vowel, streamlining the input process.
You can explore our optimized keyboard layout through the Varta Keyboard apps, available on Android and iOS, as well as through browser extensions for Chrome, Edge, and Safari.
Explore Frequency Analyses in Other Languages
We’ve performed similar analysis for other Indian languages as well. Explore them below: